
In this entry, we discuss the attention and self-attention mechanisms, two foundational mechanisms in the current most powerful LLM models.
Attention Mechanism
The attention mechanism was first introduced in 2014 by the foundational paper Attention Mechanism by Yoshua Bengio et al.
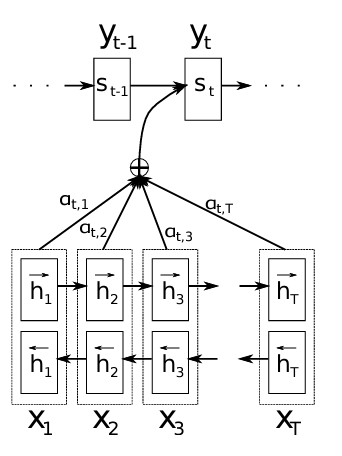
Encoder - Decoder
The architecture used comes in the form of an encoder and decoder particularly for neural translation. The output of the encoder is an annotation (concatenating forward and backward hidden states) of the RNN in the encoder. These attentions are a sequence of vectors for each input token.
Decoder
The decoder is also an RNN in which the next word prediction depends on the previous word, the hidden state and the context (from the encoder).
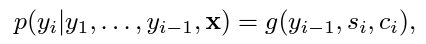
And the current hidden state in turn depends on the previous hidden state, the previous output token and the current context. Which means both the predicted token and the state are outputs of the RNN in the decoder.
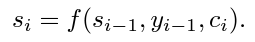
Context (using soft alignment)
We still need to define the context present in the decoder.
The context is given by the following formula:
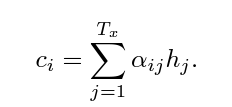
Which is just a weighted average vector, averaged across all inputs in the sequence.
To calculate the weights, they use an alignment model, modelled here as a softmax of the energies (e_ij then mapped into the weights using softmax) which depends on the last hidden state from the RNN and the current annotation.
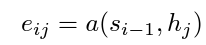
This is actually a soft alignment method because it does not focus on one input but on all of them at the same time using a weighted average.
The soft alignment model is modelled in this paper as a feed forward NN trained with the entire system.
The context is then the expected annotation of the encoder.
All these concepts (soft alignment, expected annotation, energy) and the mapping functions are the attention mechanism.
Therefore, I have modified the original diagram to add the attention mechanism.
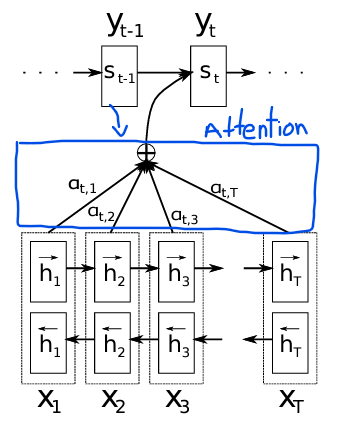
Quoted from the original paper: “The probability αij, or its associated energy eij, reflects the importance of the annotation hj with respect to the previous hidden state si−1 in deciding the next state si and generating yi. Intuitively, this implements a mechanism of attention in the decoder.”
The self attention mechanism.
In the foundational paper attention is all you need (2017), the transformer arquitecture was introduced.
This transformer arquitecture is the basis of most LLMs nowadays.
The authors introduce again an encoder - decoder architecture but it gets rid of RNNs making it more parallelizable.
In the transformer model, we replace recurrence with self attention mechanisms, in which each token pays attention to every other token in the sequence or sentence.
In RNN, you calculate embeddings that have information of the sequence calculated through memory and other sequential mechanisms which in general keeps the importance of the vecinity of each token. After this, you get the attention weights using the hidden state of the RNN of the decoder and the hidden state of the RNN in the encoder.
In the self-attention, you calculate the attention weights directly learning the Key and Query mappings (using feed forward networks) from the input (and output separately) sequence allowing each token to attend to all other tokens in the sequence.
Therefore, the attention weights are calculated using a dot product of the transformed inputs essentially reaching a matrix of attention weights where you can read how each token is paying attention to every other token in the sequence. You can pass one example and get the activations for one head in the self attention mechanism of the encoder for the last layers (there are 6 layers in this paper):
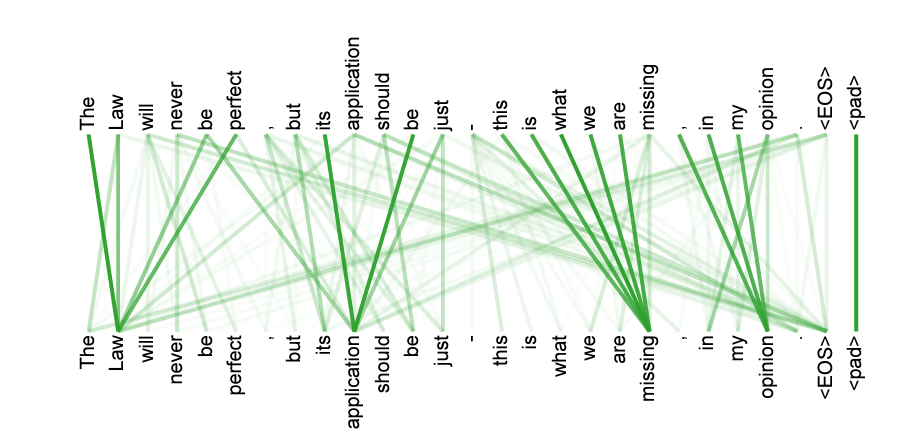
These self attention learned embeddings are used in the following architecture to compose a transformer architecture.
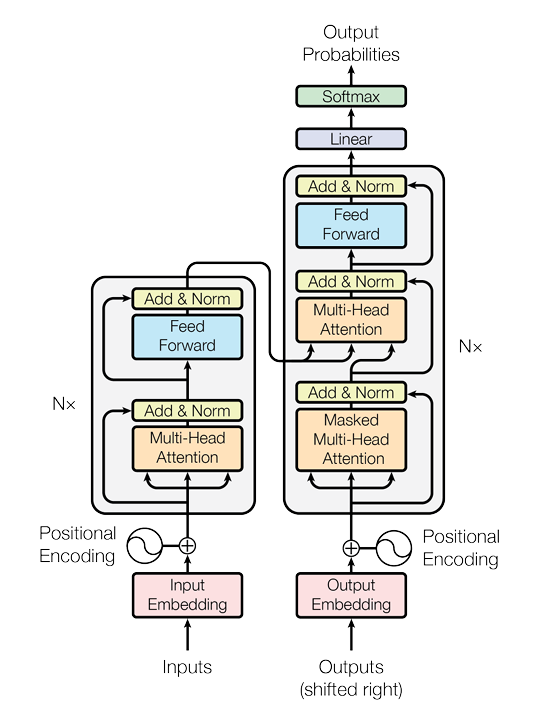
The self-attention layers can be learned in parallel to speed up computation compared to RNNs.
The positional encodings give more information of where each word is in the sequence. This positional encoder can be fixed or learned, this paper uses a sinusoid fixed positional encoder.
The transformer uses residual connections marked as lines around each part of the layers.
In the decoder, there is a masking in the first self attention component of each layer to maintain the autorregresive nature of the problem and avoid information not available at inference time.
Final Remarks
The modern Large Language Models (LLMs) are usually trained using a decoder only transformer architecture.
This makes sense since the LLMs are trained to predict the next word and therefore you don’t need to capture an embedding of the input sequence, something you would need in a seq to seq approach as in very precise machine translation models.